Pseudocode is an informal, high-level description of an algorithm written in plain English mixed with a small set of programming-style keywords. It is meant for humans to read while planning or explaining logic, and it is not run by any compiler. A short sample shows the shape of it.

IF user is logged in THEN show dashboard ELSE redirect to login
That snippet does not belong to any language. A reader who knows Python, Java, Go, or none of them can still follow what it does. Pseudocode trades the strictness of real code for readability, which is why it shows up in textbooks, whiteboard interviews, design documents, and the early notes of working programmers.
A Working Definition of Pseudocode

Pseudocode describes the steps of an algorithm using a deliberate mix of two registers. The first register supplies structure through capitalized keywords such as IF, WHILE, FOR, RETURN, and END. The second register fills in the actions and conditions in ordinary words like “show dashboard” or “if the score is over 80.” The result reads more loosely than source code and more precisely than prose.
Donald Knuth helped set the modern convention in the first volume of “The Art of Computer Programming,” published in 1968. Knuth presented algorithms with formal block structure and natural-language commentary, and that hybrid became the standard form for academic algorithm writing. Through the 1970s and 1980s, structured programming spread the same conventions into classrooms, and exam boards in the UK such as Cambridge International, AQA, and OCR each later published their own pseudocode reference for school computer science courses.
Pseudocode is not the algorithm itself. The algorithm is the abstract series of steps that solves a problem. Pseudocode is one way of writing the algorithm down on paper, alongside flowcharts, plain prose, and actual source code in a language like Python or C++.
Reasons Pseudocode Earns Its Place in Practice
Pseudocode answers a small set of recurring needs in software work. The first is planning. A programmer who writes the logic in pseudocode before opening an editor can spot dead ends or missing cases without paying the cost of language syntax, library imports, and compiler errors. The second is teaching. Computer science students learn loops and conditionals in pseudocode because the construct is visible without the clutter of semicolons, brackets, and type declarations.
The third use is communication across language boundaries. A team that includes engineers writing Go on the back end and TypeScript on the front end can agree on the same pseudocode for a validation routine, then translate it into both stacks without disagreement about logic. The fourth is documentation. Research papers, patents, and Request for Comments documents at the IETF lean on pseudocode and pseudocode-adjacent notation because reviewers come from different language backgrounds.
The last is code review and technical interviews. Walking through a function in pseudocode forces the speaker to focus on the steps that matter rather than punctuation, and it tends to surface bugs that hide inside language-specific idioms.
Rules of Good Pseudocode

Most style guides agree on a small set of rules. They are guidelines rather than absolute syntax, since no committee owns pseudocode the way standards bodies own C or HTML. The list below summarizes the conventions used in the Cal Poly Pseudocode Standard, the Cambridge International guide for teachers, and common university lecture notes.
Capitalize keywords. Words such as IF, THEN, ELSE, WHILE, FOR, DO, RETURN, BEGIN, and END appear in uppercase so they stand apart from the surrounding actions and variable names.
One operation per line. A line should hold a single step. Compound lines that wedge two ideas together hide bugs and reduce readability.
Indent nested blocks. Anything inside an IF, a WHILE, a FOR, or a function body sits one level deeper. Indentation does the work that braces or BEGIN/END pairs do in real code.
Use named variables that describe meaning. “totalScore” beats “x.” “isValidEmail” beats “flag.” A reader should understand what a variable holds without scanning back ten lines.
Stay language-agnostic. Avoid Python list comprehensions, Java generics, JavaScript arrow functions, and any other syntax that ties the description to one ecosystem.
Close every block explicitly. End multi-line constructs with ENDIF, ENDWHILE, ENDFOR, or END so the boundaries are visible at a glance, even when indentation is hard to see.
Cover the full logic. Pseudocode should not skip the hard parts. If a step says “handle the error,” the writer has not finished thinking.
Match the naming domain to the problem, not the implementation. A scheduling algorithm uses words like “appointment” and “available slot,” not “obj1” and “arr.”
These rules survive translation. Code that follows them stays readable in any target language, which is the whole point of writing in pseudocode in the first place.
Common Pseudocode Keywords

The keyword set is small, and most authors recognize the same core. The table below lists the keywords that show up in nearly every published pseudocode reference, alongside the purpose each one serves and the alternative spellings used by different style guides.
| Keyword | Purpose | Common alternatives |
| BEGIN / END | Mark the start and end of a procedure or block | START / STOP, { / } in C-style pseudocode |
| IF / THEN / ELSE / ENDIF | Conditional branching | ELSE IF, ELIF, FI |
| WHILE / ENDWHILE | Pre-test loop that runs while a condition holds | DO WHILE, WEND |
| FOR / ENDFOR | Counted loop with a known range | FOR EACH, FOREACH |
| REPEAT / UNTIL | Post-test loop that runs at least once | DO / UNTIL |
| CASE / OF / OTHERWISE | Multi-way branch | SWITCH / CASE / DEFAULT |
| INPUT / OUTPUT | Read from and write to the user | READ, PRINT, DISPLAY |
| SET / ASSIGN | Give a variable a value | left-arrow notation, := |
| CALL | Invoke a procedure or function | INVOKE, EXECUTE |
| RETURN | Send a value back from a function | OUTPUT, YIELD |
The exact list depends on the textbook or exam board. A reader who learns the column above can follow almost any pseudocode they encounter in books, lectures, or specification documents.
Pseudocode Examples Across Common Algorithms

The five examples below cover the shapes a beginner sees most often. Each one uses the keywords from the table and stays language-agnostic. The format varies on purpose, since real engineers approach pseudocode from different angles depending on the problem in front of them.
Linear Search
The problem is straightforward. Given a list of items and a target value, return the position of the target if it appears, or a sentinel value if it does not. The pseudocode walks the list from the first index to the last and returns as soon as a match appears.
FUNCTION linearSearch(list, target) FOR i FROM 0 TO length(list) – 1 IF list[i] == target THEN RETURN i ENDIF ENDFOR RETURN -1 ENDFUNCTION
The cost grows in proportion to the list size, so linear search runs in O(n) time. It works on any list, sorted or not.
Binary Search
FUNCTION binarySearch(sortedList, target) SET low TO 0 SET high TO length(sortedList) – 1 WHILE low <= high SET mid TO (low + high) / 2 IF sortedList[mid] == target THEN RETURN mid ELSE IF sortedList[mid] < target THEN SET low TO mid + 1 ELSE SET high TO mid – 1 ENDIF ENDWHILE RETURN -1 ENDFUNCTION
This version assumes the list is already sorted, which is the precondition that makes the algorithm correct. Each iteration cuts the search range in half, which gives O(log n) runtime and explains why binary search dominates linear search on large sorted data.
FizzBuzz With a Side-by-Side Translation
FizzBuzz prints the numbers from 1 to 100, replacing multiples of 3 with “Fizz,” multiples of 5 with “Buzz,” and multiples of both with “FizzBuzz.” The pseudocode and a Python translation sit side by side so the mapping is visible.
Pseudocode:
FOR i FROM 1 TO 100 IF i MOD 15 == 0 THEN PRINT "FizzBuzz" ELSE IF i MOD 3 == 0 THEN PRINT "Fizz" ELSE IF i MOD 5 == 0 THEN PRINT "Buzz" ELSE PRINT i ENDIF ENDFOR
Python:
for i in range(1, 101): if i % 15 == 0: print("FizzBuzz") elif i % 3 == 0: print("Fizz") elif i % 5 == 0: print("Buzz") else: print(i)
The structure is identical line for line. The pseudocode reads slightly slower because of the explicit ENDIF and ENDFOR, and the Python code reads slightly faster because indentation alone marks the block. The logic is the same in both.
Input Validation, Buggy and Fixed
Pseudocode rewards careful reading because errors hide in the same places they do in real code. The version below tries to validate that a password meets two requirements: at least 8 characters and at least one digit. It contains a bug.
FUNCTION isValid(password) IF length(password) < 8 THEN RETURN false ENDIF FOR each character c IN password IF c IS a digit THEN RETURN true ENDIF ENDFOR ENDFUNCTION
The bug sits at the bottom. If the loop ends without finding a digit, the function returns nothing. A reader cannot tell what the caller will see. The fix adds an explicit RETURN at the end so every path produces a value.
FUNCTION isValid(password) IF length(password) < 8 THEN RETURN false ENDIF FOR each character c IN password IF c IS a digit THEN RETURN true ENDIF ENDFOR RETURN false ENDFUNCTION
Missing return paths are one of the most common pseudocode mistakes during interviews. The “complete logic” rule from earlier in the article exists to catch exactly this kind of gap.
Factorial Through Recursion
Recursion gives pseudocode a chance to show a function calling itself. The factorial of n, written n!, is the product of every integer from 1 to n. The recursive definition is short: 0! and 1! both equal 1, and n! for any larger n equals n times (n-1)!. The pseudocode follows the definition.
FUNCTION factorial(n) IF n <= 1 THEN RETURN 1 ELSE RETURN n * factorial(n – 1) ENDIF ENDFUNCTION
The first branch is the base case, and the second branch is the recursive call. Every recursive function needs both. A function without a base case runs forever, and a function without a recursive call does no recursion at all. The pseudocode here translates directly into Python, JavaScript, Ruby, or any other language that supports function calls.
Pseudocode, Flowcharts, and Source Code Compared
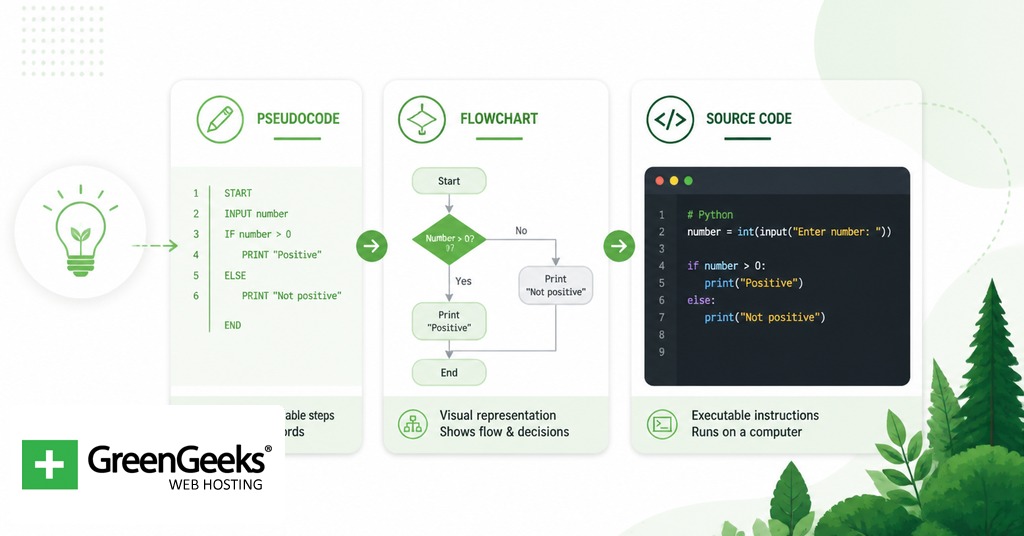
These three artifacts describe the same logic in different ways. A beginner picks one based on the audience and the size of the algorithm. The table below summarizes the trade-offs.
| Feature | Pseudocode | Flowchart | Source code |
| Format | Text with keywords | Diagram with shapes | Text with strict syntax |
| Audience | Programmers and CS students | Mixed audiences, including non-programmers | Compilers and interpreters |
| Editing | Easy to edit in any text tool | Harder to edit once drawn | Easy to edit, validated by compiler |
| Scales to long algorithms | Yes | Becomes unwieldy past 10–15 boxes | Yes |
| Executable | No | No | Yes |
| Implementation detail | Hidden | Hidden | Visible |
Flowcharts work well for short procedures shown to stakeholders who do not read code. Pseudocode handles longer algorithms and reads naturally to engineers. Source code is the only one of the three a computer can run. Most teams use more than one of these artifacts during a project, and the move from pseudocode to source code is usually the last step before testing.
Common Mistakes in Pseudocode

Beginner pseudocode tends to fail in a small number of repeating ways. The first mistake is leaning on language-specific syntax. Writing list.append(x) or arr.length inside pseudocode pulls the reader into a particular language and breaks the language-agnostic rule.
The second mistake is using vague variable names. “data,” “value,” and “result” appear so often that they lose meaning. A reader who sees “averageGrade” or “remainingDays” understands the variable without context.
The third mistake is skipping difficult steps with phrases like “and then sort the list” or “validate the input.” Pseudocode that hides the hard part is not pseudocode, it is an outline. The fix is to expand each handwave into its own block.
The fourth is forgetting the closing keyword on a block. A FOR without an ENDFOR, or an IF without an ENDIF, leaves the reader guessing where the block ends. Indentation helps, but indentation alone is fragile in plain text where alignment can drift.
The last is writing decorative sentences instead of operations. “We carefully check each item” is not a step. “FOR each item, IF item is invalid THEN reject the request” is. Pseudocode is for operations, not commentary.
Frequently Asked Questions

Is pseudocode case sensitive?
Pseudocode is generally treated as case insensitive. Variable names like Countdown and countdown refer to the same value in most style guides. Convention encourages uppercase keywords (IF, WHILE, FOR) and mixed-case identifiers (numberOfPlayers) for readability, but the rule is stylistic rather than enforced.
What is the difference between pseudocode and a flowchart?
Pseudocode is text. A flowchart is a diagram built from shapes such as rectangles for processes and diamonds for decisions. Both describe the same algorithm, but pseudocode reads faster for programmers and scales to longer logic, while a flowchart communicates better to mixed audiences and shorter procedures.
Is there a standard syntax for pseudocode?
There is no single global standard. Cambridge International, AQA, OCR, and academic textbooks each publish their own conventions, and they differ on small points such as which loop terminators to use. Most styles share the same core keywords (IF, WHILE, FOR, RETURN) and indentation rules, so a reader who learns one style can follow the others without much trouble.
Who invented pseudocode?
No single person invented pseudocode. The form grew through the 1960s and 1970s alongside structured programming. Donald Knuth’s “The Art of Computer Programming,” with the first volume published in 1968, established the dominant convention for describing algorithms in academic work, and the practice spread from there into classrooms and industry documentation.
Can pseudocode be converted to code?
Yes. Pseudocode is often the first draft of an algorithm, and a programmer translates each line into a target language such as Python, Java, or C. The closer the pseudocode is to a real language, the more direct the translation. Loose pseudocode written in near-prose may need more interpretation, but the logical steps still map onto language constructs one for one.

